
“The more complex and lengthy the suggestion, the more likely it has some sort of copyrightable expression.”

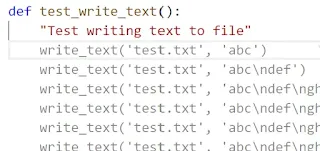

I also had Copilot create a test using the same basic approach as above, and it wrote:
That test doesn’t actually pass, since getnames in the last line includes the parent directory, but it’s an easy enough fix from there. Copilot even cleverly decided to use the write_text function I created earlier, which is something I wasn’t expecting.
You can even use Copilot to write prose. I’m writing this blog post in vscode right now, and just clicked the “enable Copilot” button. After I typed the previous sentence, here’s what Copilot recommended as a completion:
I can now write my blog post in a single line of text, and Copilot will generate the rest of the post for me
Clearly Copilot has a rather inflated understanding of its own prose generation capabilities!
Code Problems
The code Copilot writes is not very good code. For instance, consider the tar_dir function above. There’s a lot of duplicate code there, which means more code to maintain in the future, and more code for a reader to understand. In addition, the docstring said “optionally compress”, but the generated code always compresses. We could fix these issues by writing it this way instead:
A bigger problem is that both write_text and tar_dir shouldn’t have been written at all, since the functionality for both is already provided by Python’s standard library (as pathlib’s write_text and shutil’s make_archive). The standard library versions are also better, with pathlib’s write_text doing additional error checking and supporting text encoding and error handling, and make_archive supporting zip files and any other archive format you register.
Walk-through
Before we dive into Copilot more deeply, let’s walk-through some more examples of using it in practice.
In order to know whether that auto-generated write_text function actually works, we need a test. Let’s get Copilot to write that too! In this case, I just typed in the name of my test function, and Copilot filled in the docstring for me:
Why Copilot writes bad code
According to OpenAI’s paper, Codex only gives the correct answer 29% of the time. And, as we’ve seen, the code it writes is generally poorly refactored and fails to take full advantage of existing solutions (even when they’re in Python’s standard library).
Copilot has read GitHub’s entire public code archive, consisting of tens of millions of repositories, including code from many of the world’s best programmers. Given this, why does Copilot write such crappy code?
The reason is because of how language models work. They show how, on average, most people write. They don’t have any sense of what’s correct or what’s good. Most code on GitHub is (by software standards) pretty old, and (by definition) written by average programmers. Copilot spits out it’s best guess as to what those programmers might write if they were writing the same file that you are. OpenAI discuss this in their Codex paper:
“As with other large language models trained on a next-token prediction objective, Codex will generate code that is as similar as possible to its training distribution. One consequence of this is that such models may do things that are unhelpful for the user”
One important way that Copilot is worse than those average programmers is that it doesn’t even try to compile the code or check that it works or consider whether it actually does what the docs say it should do. Also, Codex was not trained on code created in the last year or two, so it’s entirely missing recent versions, libraries, and language features. For instance, prompting it to create fastai code results only in proposals that use the v1 API, rather than v2, which was released around a year ago.
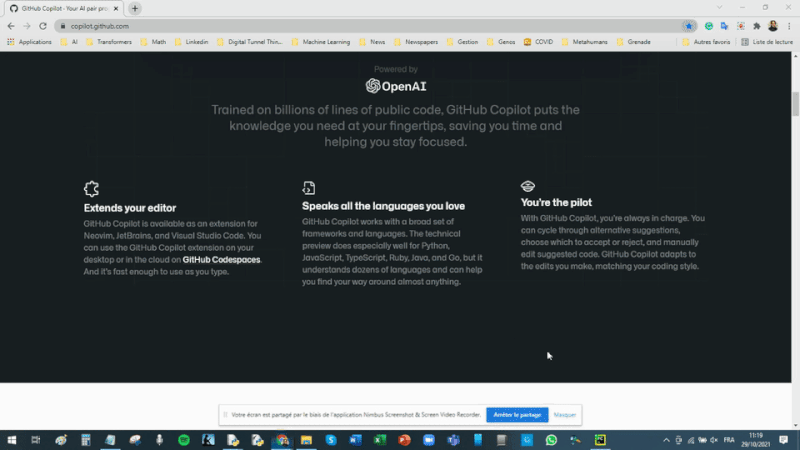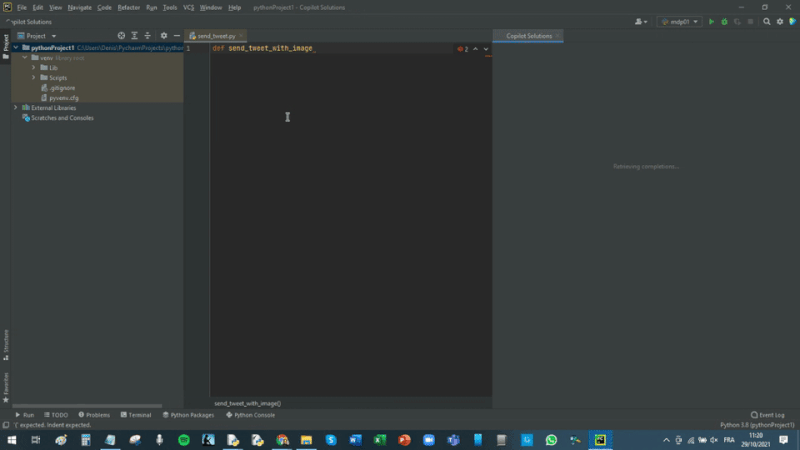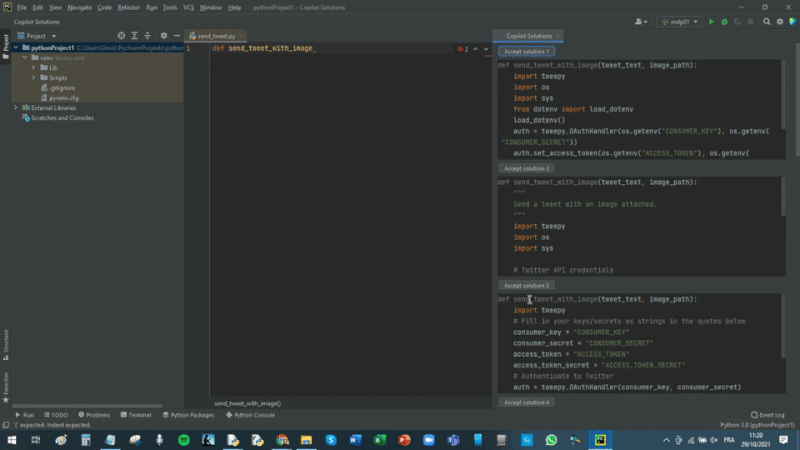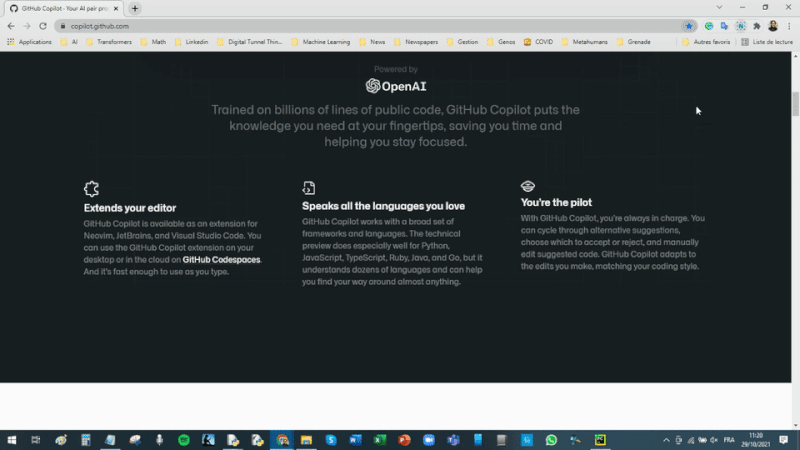
Complaining about the quality of the code written by Copilot feels a bit like coming across a talking dog, and complaining about its diction. The fact that it’s talking at all is impressive enough!
Let’s be clear: The fact that Copilot (and Codex) writes reasonable-looking code is an amazing achievement. From a machine learning and language synthesis research point of view, it’s a big step forward.
But we also need to be clear that reasonable-looking code that doesn’t work, doesn’t check edge cases, and uses obsolete methods, and is verbose and creates technical debt, can be a big problem.
Conclusions
I still don’t know the answer to the question in the title of this post, “Is GitHub Copilot a blessing, or a curse?” It could be a blessing to some, and a curse to others. For those for whom it’s a curse, they may not find that out for years, because the curse would be that they’re learning less, learning slower, increasing technical debt, and introducing subtle bugs – are all things that you might well not notice, particularly for newer developers.
Copilot might be more useful for languages that are high on boilerplate, and have limited meta-programming functionality, such as Go. (A lot of people today use templated code generation with Go for this reason.) Another area that it may be particularly suited to is experienced programmers working in unfamiliar languages, since it can help get the basic syntax right and point to library functions and common idioms.
The thing to remember is that Copilot is an early preview of a very new technology that’s going to get better and better. There will be many competitors popping up in the coming months and years, and GitHub will no doubt release new and better versions of their own tool.
To see real improvements in program synthesis, we’ll need to go beyond just language models, to a more holistic solution that incorporates best practices around human-computer interaction, software engineering, testing, and many other disciplines. Currently, Copilot feels like a product designed and implemented by machine learning researchers, rather than a complete solution incorporating all needed domain expertise. I’m sure that will change.